Figure 1: Order Table - 1NF

The problem here is the danger of introducing errors, called data anomalies, into the table. Data anomalies can be introduced by operator error or through programming. Once you have a single data anomaly in your table, all of your data is suspect, so the remaining normal forms work to remove such data anomalies. Figure 2 shows the same table with data anomalies present.
Figure 2: Order Table with Data Anomalies Present

As you can see, Order 112 has two different customer numbers (444 and 445), which is correct? It is impossible to tell. In addition, both product numbers B7G and B7H are identified as a 'saw'. Are these the same product with different product numbers or different products with the same description? Again, I can't know based on the data in the database.
The root cause of these data anomalies is redundant data, that is, data that is repeated in multiple rows. So we need to minimize this redundant data as much as possible.
Now wait a second! Didn't I just say in the last post that I HAD to repeat the values? Yes I did. But that was to comply with 1NF, which is not the end of the story.
Definition
So let's look at the definition of Second Normal Form (2NF). A table is said to be in 2NF if:
- It is in 1NF.
- Every field is functionally dependant on the entire primary key, that is, it depends on the entire primary key for its value.
Functional Dependency
Before I can continue, I have to talk a bit about functional dependencies, because all of the remaining normal forms rely on this concept. Functional dependency speaks to the relationship that fields in a table have to each other. It is perhaps best explained by example.
Suppose there is an Employee table, and I am an entity in that table. There is a row that represents all the information about Roger Carlson with Social Security Number (SSN) acting as the primary key. Since all the fields in my row are information about me, and I am represented by the SSN, we can say that each field depends on SSN for its value. Another way to say it is that SSN implies the value of each of the other fields in my record.
If a different row is selected, with a different SSN, the values of all the other fields will change to represent that entity.
Implications
Second Normal Form says that all of the fields in a table must depend on the ENTIRE primary key. When there is a single primary key (like SSN), it is pretty simple. Each field must be a fact about the record. But when there is a compound primary key, it's possible that some fields may depend on just part of the primary key.
Going back to our Order Table example, Figure 3 shows these partial dependencies.
Figure 3: 1NF Orders Table showing dependencies

In order to uniquely identify the record, the primary key of this table is a combination of OrderNum and ProductNum (or Item, but a number is a better choice).
2NF says that each field must depend on the ENTIRE primary key. This is true for some fields: Quantity depends on both the OrderNum and ProductNum, so does Item. However, some fields do not.
Order 112 will be for customer 444 regardless of the product selected. The order date does not change when the product number changes either. These fields depend ONLY on the OrderNum field.
Since some fields do not depend on the entire primary key, it is not in Second Normal Form. So what do I do about it?
Implementation
The solution is to remove those records, which do not depend on the entire primary key, to a separate table where they do. In the process, I remove the redundant or repeated data so there is just a single record for each. Figure 4 shows the process of decomposing the table into two tables.
Figure 4: 1NF Orders table Decomposed to 2NF

This corrects the data anomaly with the two different customers for the same order. However, I still have the problem of the product number and the item description. It's still possible for the same product to have different descriptions or different items sharing the same ProductNum, as Figure 5 illustrates.
Figure 5: Remaining data anomalies.

Product A7S is either a wrench or a nail, and a saw is either product number B7G or B7H.
To correct these problems, I need to add yet another normal form: Third Normal Form. I'll talk about that next.
.














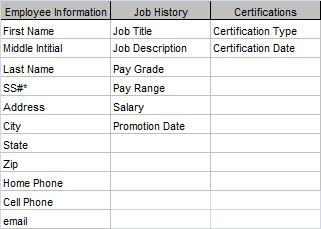
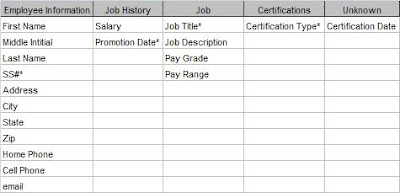
 Now I can see where to put my unassigned Certification Date field. The Employee/Certification entity represents a certification for a particular employee and that can be given at only one time. Therefore the Certification Date field goes in this new entity. Figure 3 shows the completed Attribute Grid.
Now I can see where to put my unassigned Certification Date field. The Employee/Certification entity represents a certification for a particular employee and that can be given at only one time. Therefore the Certification Date field goes in this new entity. Figure 3 shows the completed Attribute Grid.

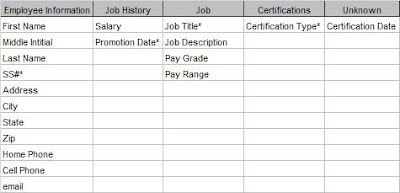





 Employee-Certifications
Employee-Certifications Job-Certifications
Job-Certifications Each certification is only for a single job. It is important to verify this with the client. If a certification were required for many different jobs, the model would be different, but in this case it is for only one job. The certification requirements for Analyst I are different than for Analyst II.
Each certification is only for a single job. It is important to verify this with the client. If a certification were required for many different jobs, the model would be different, but in this case it is for only one job. The certification requirements for Analyst I are different than for Analyst II.