In What Is Normalization: Parts I, II, III, IV and V, I discussed the decomposition method of normalization, where you put all your fields into a single table and break the them down into smaller, normalized tables.
In Entity-Relationship Diagramming: Parts I, II, III, and IV, I discussed an alternate method which works from the bottom up. It takes the individual pieces of information (Attributes) and group them into logical groupings (Entities).
However, in neither case did I formally define or explain the Normal Forms. And that's for good reason. I find that only after people get a working understanding of normalization do they really understand the Normal Forms and what they imply. Therefore I usually leave them until last. If you haven't read the above mentioned serie, it would be worth your while to do so.
Normalization was first developed by E. F. Codd, the father of Relational Database theory. He created a series of "Normal Forms", which mathematically defined the rules for normalization. Each normal form is "stronger" than the previous, that is, they build upon the previous normal forms. Second Normal Form (2NF) encompasses all the rules of First Normal Form (1NF) plus adding its own rules. Third Normal Form encompasses all of 1NF and 2NF, and so on.
Figure 1: Each Normal Form Encompasses the Previous

In order, the normal forms are: First Normal Form (1NF), Second Normal Form (2NF), Third Normal Form (3NF), Boyce-Codd Normal Form (BCNF), Fourth Normal Form (BCNF), Fifth Normal Form (5NF), and Domain Key Normal Form (DKNF). BCNF comes between 3NF and 4NF because it was developed later, but because of its "strength" belonged between 3NF and 4NF.
Since each normal form encompasses all previous forms, in theory, the higher the normal form, the "better" the database.
In practice, however, normalizing to the first three normals form will avoid the vast majority of database design problems. So it is generally agreed that to be properly normalized, most databases must be in 3NF.
Beyond 3NF, the normal forms become increasingly specialized. Boyce-Codd Normal form and Fourth Normal Form were created to handle special situations. Fifth Normal Form and Domain-Key Normal Form are largely of theoretical intererst and little used in practical design.
So what I'm going to do for this series is limit myself to the first three normal forms, giving their definitions, implications for data, and how to implement them.
In my next post, I'll start with the First Normal Form.







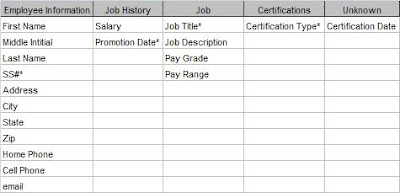
 Now I can see where to put my unassigned Certification Date field. The Employee/Certification entity represents a certification for a particular employee and that can be given at only one time. Therefore the Certification Date field goes in this new entity. Figure 3 shows the completed Attribute Grid.
Now I can see where to put my unassigned Certification Date field. The Employee/Certification entity represents a certification for a particular employee and that can be given at only one time. Therefore the Certification Date field goes in this new entity. Figure 3 shows the completed Attribute Grid.

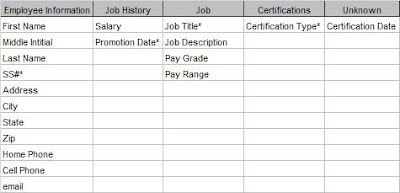





 Employee-Certifications
Employee-Certifications Job-Certifications
Job-Certifications Each certification is only for a single job. It is important to verify this with the client. If a certification were required for many different jobs, the model would be different, but in this case it is for only one job. The certification requirements for Analyst I are different than for Analyst II.
Each certification is only for a single job. It is important to verify this with the client. If a certification were required for many different jobs, the model would be different, but in this case it is for only one job. The certification requirements for Analyst I are different than for Analyst II.