Break it up. Break it up.
In What Is Normalization, Part I, I discussed various ways to represent data in a tabular form. All of those methods have problems -- from not storing enough data, to storing redundant data, to allowing data anomalies.
The Relational Database Model was created by Edgar F. Codd specifically to solve those problems. The foundation of the Relational Model is a process Codd dubbed "Normalization". It is the process of grouping related data elements into separate tables and then relating those tables on common data elements.
Since an example is worth a thousand cliches, let's look again at the example from Part I.
Figure 1: Salary History
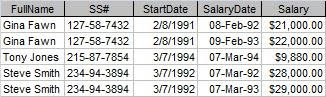 Figure 1 shows the salary history of a small company. As is, it represents the lowest level of data organization a table must have in a database. Codd called this level the First Normal Form (1NF). (Don't worry, I'm not going to explain all the normal forms.)
Figure 1 shows the salary history of a small company. As is, it represents the lowest level of data organization a table must have in a database. Codd called this level the First Normal Form (1NF). (Don't worry, I'm not going to explain all the normal forms.)Another rule of Normalization says that all of the fields in a table should be about just one "thing". But a look at Salary History reveals that some of the fields are not really about the salary history at all.
How do I know? Well, we can't talk about normalization without discussing primary keys. (See What is a Primary Key for a more detailed discussion.) The way that we can tell if all of the fields are about the same "thing" is by seeing if all the fields in the record depend on the entire primary key.
In Figure 1, we can see that the fields necessary to uniquely identify the record are SS# and SalaryDate (the date on which the salary increase was given.) But do FirstName and StartDate depend on the ENTIRE primary key? No, they do not. FirstName or StartDate do not change if the SalaryDate changes.
Therefore we need to move them to a different table. What table? Well, what are the fields about? In this case, they are about the employee, so we will create an employee table composed of FullName, SS#, and StartDate. SS# is the most obvious choice for a primary key in this example. (Note: Social Security number is NOT usually the best choice for a primary key in real life.)
Do FullName and StartDate depend on SS#? Yes they do. The SS# represents a single, real-life person and that person can have only one name and one start date.
Now we are left with three fields in Salary History: SS#, SalaryDate, and Salary. SS# and SalaryDate remain the primary key. Does Salary depend the entire primary key? Again, yes. Each person can have only one Salary increase on a particular date.
So normalizing the table structure requires two tables: Employee and Salary History, like so:
Figure 2: Employee
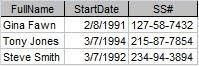
Figure 3: Salary History

Of course, now we have to somehow put the data back together. For that, we need Relationships. We'll look at that next time in What is Normalization, Part III.
.
No comments:
Post a Comment