In the first post of this series, Select Queries Part 1: Simple Queries, I talked about creating simple queries with the first two sections of a Select Query, the SELECT clause and the FROM clause. In the second post, Select Queries Part 2: Restricting Rows - the Where Clause, I discussed how to restrict rows returned with the WHERE clause. This time, I'm going to discuss how to sort your results with the ORDER BY clause and how to aggregate your data with the GROUP BY clause.
ORDER BY Clause
Tables in relational databases like Access (or SQL Server or Oracle, for that matter) do not have any intrinsic order. This means they can be returned in any order, not necessarily the order they were entered or that they appear when you open the table. So if you want them in a particular order, you have to sort them yourself. You do that in a query in the ORDER BY clause.
The ORDER BY clause has two parts: [field] [ASC/DESC] (repeat for as many fields as you need).
The [field] designates the field on which the sort will be performed and [ASC/DESC] tells how the field will be sorted. ASC means ascending (smallest to largest). DESC means descending (largest to smallest). ASC is the default, so if you don't designate an order, it will be smallest to largest.
Letters are sorted alphabetically A-Z (or Z-A if DESC). Numbers are sorted numerically. This is all very obvious until you have numbers that are stored as text. While they look like numbers, they will not sort numerically. For instance, these character strings sorted alphabetically:
CustomerNum
-----------
101
102
1100
201
3001
301
One solution is to add leading zeros to your text numbers. Numeric data will not save leading zeros, but text will:
CustomerNum
-----------
0101
0102
0201
0301
1100
3001
Later on, I'll discuss another method that does not require altering your data.
The Order By clause follows the Where clause:
SELECT ProductName, Cost, Price, [Price]-[Cost] AS Margin
FROM Products
WHERE ProductName = "hammer"
ORDER BY Cost DESC
Examples of ORDER BY clauses:
ORDER BY ProductName (Products alphabetically A-Z)
ORDER BY [Price]-[Cost]DESC (margin highest to lowest)
ORDER BY ProductName, Cost DESC
The last example shows that you can also sort on multiple fields. In this case, the table will be sorted on ProductName (ascending) and within each group of products, it will be sorted on Cost (descending).
ProductName Cost
----------- ----
Ax $3
Hammer $15
Hammer $10
Wrench $5
Wrench $4
The fields in the ORDER BY clause do not have to be in the Field List of the SELECT clause. For instance, this will work just fine:
SELECT ProductName
FROM Products
ORDER BY Cost
In the Query Builder, simply uncheck the checkbox to do this:
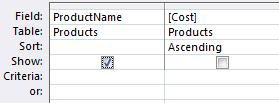
You can also sort on an expression. I showed [Price]-[Cost], but you can also apply functions to your fields. For instance, earlier I showed how text numbers will sort incorrectly. I showed how leading zeros will correct it, but another solutions is to display the text numbers as they are in the field list, but to add a function to the ORDER BY clause that converts them to numeric.
SELECT [CustomerNum]
FROM Customer
ORDER BY CLng([CustomerNum]);
CLng () is a built-in function that converts Text to Long Integer.
GROUP BY and HAVING Clauses
The GROUP BY and HAVING clauses are used with "Totals" or Aggregate queries.
The GROUP BY allows you to group your data and apply a function to the grouped data. For instance:
SELECT ProductName, Cost
FROM Products
Will result in the following:
ProductName Cost
----------- ----
Ax $3
Wrench $4
Hammer $15
Wrench $5
Hammer $10
However, if I wanted to see the average cost for each group, I could add a GROUP BY clause:
SELECT ProductName, Cost
FROM Products
GROUP BY ProductName, Avg(Cost)
ProductName Cost
----------- ----
Ax $3
Wrench $ 4.5
Hammer $ 12.5
Every field in the Field List MUST be represented in the GROUP BY clause either to group on or with an aggregate function. Examples of aggregate functions are: Sum, Avg, Min, Max, and Count.
The HAVING clause works like the WHERE clause, but it restricts rows after they have been grouped.
SELECT ProductName, Cost
FROM Products
GROUP BY ProductName, Avg(Cost)
HAVING Avg(Cost)
Will return:
ProductName Cost
----------- ----
Wrench $ 4.5
Hammer $ 12.5
There's a lot more to be said about Totals Queries, and I'll do that in greater depth in a later post.
Next time, in Select Queries: Part 4, I'll finish up the Select Query with some odds and ends: Top Query, Distinct Query, Crosstab Query and Parameters.
.








![image_thumb[10]](https://lh3.googleusercontent.com/-Ajqf9IT9IBw/Vp4lH2ITCmI/AAAAAAAAB44/VZDJun0Ke_c/s1600-h/image_thumb%25255B10%25255D%25255B2%25255D.png "image_thumb[10]")
![image_thumb[8]](https://lh3.googleusercontent.com/-USzO1rC3WCY/Vp4lKHPldeI/AAAAAAAAB5I/BuaxKsiQk1M/s1600-h/image_thumb%25255B8%25255D%25255B2%25255D.png "image_thumb[8]")