Tuesday, December 15, 2015
Union Query: Part 2
More Union Queries
Last time in Union Queries: Part 1, I discussed simple Union queries and some of their uses. This time I want to talk about some advanced topics, starting with Union All.
Union Vs. Union All
As you remember from last time, a Union query takes the result of one query and "appends" it to another. At the same time, it removes duplicates and orders the records on the first field in the field list.
The Union All does the same thing as the Union, but without removing the duplicates or sorting the resultset, so:
SELECT * FROM TableA
UNION ALL
SELECT * FROM TableB
Would return:
CustomerID CreditLimit
---------- -----------
1001 $500
1010 $350
1017 $375
1020 $425
1017 $375
1008 $600
The order is not determined by the base tables. The result has no order, so the records could be returned in any order.
Sorting Union Queries
So what if you want to sort your Union All or want a different sort order for your Union? Like any Select query, you can add an Order By clause to the end.
SELECT CustomerID, CreditLimit
FROM TableA
UNION ALL
SELECT CustomerID, CreditLimit
FROM TableB
ORDER BY CustomerID;
Will return:
CustomerID CreditLimit
---------- -----------
1001 $500
1008 $600
1010 $350
1020 $425
1017 $375
1017 $375
The Order By applies to the entire result. If the column names are different between queries (which, you'll remember, I said was allowable), the column names from the *first* query must be used. Order By clauses in any of the other component queries will be ignored. Only the last one will be applied.
Restricting Rows
Like any other Select query, you can restrict rows from the resultset with a Where clause. Unlike the Order By, however, each component query can have its own criteria. If you put a Where clause on the last query, it will apply to ONLY the results of the last query. So this:
SELECT CustomerID, CreditLimit
FROM TableA
UNION
SELECT CustomerID, CreditLimit
FROM TableB
WHERE CreditLimit > 500
Produces this:
CustomerID CreditLimit
---------- -----------
1001 $500
1008 $600
1010 $350
1017 $375
Since 1010 and 1017 are in TableA, they can be less than 500, whereas 1020 is in TableB, so it is restricted. If you want a Where to apply to the entire resultset, you have to put it in each query.
SELECT CustomerID, CreditLimit
FROM TableA
WHERE CreditLimit > 500
UNION
SELECT CustomerID, CreditLimit
FROM TableB
WHERE CreditLimit > 500
Tables With Unequal Numbers Of Columns
As I said, the individual queries don't have to have the same column names, nor do they have to be the same datatype, but the *number* of columns in the field list must be equal.
What if your tables have unequal columns? In that case, you need to create false columns with an alias.
So suppose you have two tables which hold much the same data, but have slightly different structures.*
TABLE A
CustomerID CreditLimit
---------- -----------
1001 $500
1010 $350
1017 $375
TABLE B
CustomerNum Credit Active
---------- ------ ------
1008 $600 Y
1017 $375 Y
1020 $425 Y
*Please Note: I am not advocating this as a good database design. In a properly designed database, you would never have two tables which stored the same type of data. However, you may find yourself in this situation if you are fixing a poorly designed database or if you are merging separate databases.
If I don't know the value of "Active" for TableA, I can leave the value NULL.
SELECT CustomerID, CreditLimit, NULL AS Active
FROM TableA
UNION
SELECT CustomerNum, Credit, Active
FROM TableB;
CustomerID CreditLimit Active
---------- ----------- ------
1001 $500
1008 $600 Y
1010 $350
1017 $375 Y
1020 $425 Y
However, if I assume all of the customers in TableA are active
SELECT CustomerID, CreditLimit, "Y" AS Active
FROM TableA
UNION
SELECT CustomerNum, Credit, Active
FROM TableB;
CustomerID CreditLimit Active
---------- ----------- ------
1001 $500 Y
1008 $600 Y
1010 $350 Y
1017 $375 Y
1020 $425 Y
Because Union Queries cannot be viewed in the Query Builder, they are often over looked by Access novices, but they are a powerful tool to have in your SQL arsenal.
.
Tuesday, December 8, 2015
Union Query: Part 1
Simple Union Query
Introduction
In Microsoft Access, a Union Query is an SQL Specific query, which means it can only be written in SQL. It cannot be created or edited in the Access Query Builder. Novices often confuse UNIONS with JOINS.
Joins (see What is a Join: Part 1 and subsequent posts) combine two (or more) tables row-wise, that is, the results of matching information will be displayed on a single row.
Unions, on the other hand, combine tables column-wise, that is, the results of one SQL statement will be "appended" to the results of another as additional rows. In essence, a Union sticks the results of one query on to the bottom of another.
The structure of a Union Query is very simple. It is two or more queries with the UNION keyword in between. For instance:
SELECT Field1, Field2 FROM Table1
UNION
SELECT FieldA, FieldB FROM Table2
As you can see from the example, the field names do not need to be the same. The column name in the result will come from the first query. The fields don't even need to be the same datatype. In the query above, Field1 could be an integer, Field2 a date/time, FieldA a text field, and FieldB a currency field.
The only real requirement is that there must be an equal number of columns in each of the component SQL statements. If there are different numbers of fields in the field lists, an error will occur.
One important thing to remember about the Union is that it is non-updateable (for more on this see: (This Recordset Is Not Updateable. Why?). As a result, Unions are useful for displaying data, but not for entering or editing it.
Union Example
One of the most common uses for a Union query is to consolidate tables.
For example, imagine a situation where you have similar datasets from 2 different sources, and you want to consolidate/synchronize/merge them:
TABLE A
CustomerID CreditLimit
---------- -----------
1001 $500
1010 $350
1017 $375
TABLE B
CustomerID CreditLimit
---------- -----------
1008 $600
1017 $375
1020 $425
This query:
SELECT CustomerID, CreditLimit FROM TableA
UNION
SELECT CustomerID, CreditLimit FROM TableB
Will produce this result:
CustomerID CreditLimit
---------- -----------
1001 $500
1008 $600
1010 $350
1017 $375
1020 $425
The Union combines the two tables, while at the same time removing the duplicate records. The Union also sorts the recordset on the first column, in this case CustomerID.
Since TableA and TableB have the same number of fields, I could also have done this:
SELECT * FROM TableA
UNION
SELECT * FROM TableB
To actually consolidate the tables into a single table, save the query (say, CustomerUnion), then use it as the table in a Make-Table query.
SELECT * INTO TableC FROM CustomerUnion;
Or use the Union Query in the "From" clause of the Make-Table:
SELECT * INTO TableC
FROM
(SELECT * FROM TableA
UNION
SELECT * FROM TableB)
AS CustomerUnion;
(I'll discuss using a query in the From clause in more detail in a later post.)
Other Uses
There are many applications for the Union Query. One is in the Access implementation of a Full Outer Join (which I will address in a later post). But one very common use is in the Row Source of Combo Boxes.
Suppose I have a combo box to filter records on a form by Customer Name.

My Row Source for the combo could look like this:
SELECT CustomerID, CustomerName FROM Customer;
But suppose I want the combo to have an option to choose all records.

I can use a Union query in the Row Source to add artificial records to the drop down list:
SELECT "*" as CustomerID, "All" as CustomerName FROM Customer
UNION
SELECT CustomerID, CustomerName FROM Customer;
This will produce a result of
CustomerID CustomerName
---------- -----------
* All
1010 Carlson
1017 Smith
With CustomerID as the bound column in the combo box, I can use a query like:
SELECT * FROM TableA
WHERE CustomerID Like '" & Combo1 & "'"
to filter my form.
Next time, I'll look at some advanced topics with Union Queries.
.
Introduction
In Microsoft Access, a Union Query is an SQL Specific query, which means it can only be written in SQL. It cannot be created or edited in the Access Query Builder. Novices often confuse UNIONS with JOINS.
Joins (see What is a Join: Part 1 and subsequent posts) combine two (or more) tables row-wise, that is, the results of matching information will be displayed on a single row.
Unions, on the other hand, combine tables column-wise, that is, the results of one SQL statement will be "appended" to the results of another as additional rows. In essence, a Union sticks the results of one query on to the bottom of another.
The structure of a Union Query is very simple. It is two or more queries with the UNION keyword in between. For instance:
SELECT Field1, Field2 FROM Table1
UNION
SELECT FieldA, FieldB FROM Table2
As you can see from the example, the field names do not need to be the same. The column name in the result will come from the first query. The fields don't even need to be the same datatype. In the query above, Field1 could be an integer, Field2 a date/time, FieldA a text field, and FieldB a currency field.
The only real requirement is that there must be an equal number of columns in each of the component SQL statements. If there are different numbers of fields in the field lists, an error will occur.
One important thing to remember about the Union is that it is non-updateable (for more on this see: (This Recordset Is Not Updateable. Why?). As a result, Unions are useful for displaying data, but not for entering or editing it.
Union Example
One of the most common uses for a Union query is to consolidate tables.
For example, imagine a situation where you have similar datasets from 2 different sources, and you want to consolidate/synchronize/merge them:
TABLE A
CustomerID CreditLimit
---------- -----------
1001 $500
1010 $350
1017 $375
TABLE B
CustomerID CreditLimit
---------- -----------
1008 $600
1017 $375
1020 $425
This query:
SELECT CustomerID, CreditLimit FROM TableA
UNION
SELECT CustomerID, CreditLimit FROM TableB
Will produce this result:
CustomerID CreditLimit
---------- -----------
1001 $500
1008 $600
1010 $350
1017 $375
1020 $425
The Union combines the two tables, while at the same time removing the duplicate records. The Union also sorts the recordset on the first column, in this case CustomerID.
Since TableA and TableB have the same number of fields, I could also have done this:
SELECT * FROM TableA
UNION
SELECT * FROM TableB
To actually consolidate the tables into a single table, save the query (say, CustomerUnion), then use it as the table in a Make-Table query.
SELECT * INTO TableC FROM CustomerUnion;
Or use the Union Query in the "From" clause of the Make-Table:
SELECT * INTO TableC
FROM
(SELECT * FROM TableA
UNION
SELECT * FROM TableB)
AS CustomerUnion;
(I'll discuss using a query in the From clause in more detail in a later post.)
Other Uses
There are many applications for the Union Query. One is in the Access implementation of a Full Outer Join (which I will address in a later post). But one very common use is in the Row Source of Combo Boxes.
Suppose I have a combo box to filter records on a form by Customer Name.

My Row Source for the combo could look like this:
SELECT CustomerID, CustomerName FROM Customer;
But suppose I want the combo to have an option to choose all records.

I can use a Union query in the Row Source to add artificial records to the drop down list:
SELECT "*" as CustomerID, "All" as CustomerName FROM Customer
UNION
SELECT CustomerID, CustomerName FROM Customer;
This will produce a result of
CustomerID CustomerName
---------- -----------
* All
1010 Carlson
1017 Smith
With CustomerID as the bound column in the combo box, I can use a query like:
SELECT * FROM TableA
WHERE CustomerID Like '" & Combo1 & "'"
to filter my form.
Next time, I'll look at some advanced topics with Union Queries.
.
Thursday, December 3, 2015
Select Queries Part 4: PARAMETERS, TOP, DISTINCT, and TRANSFORM...PIVOT
This is my final post in this series about Select Queries.
In Select Queries Part 1: Simple Queries, I discussed the SELECT and FROM clauses. In Select Queries Part 2: Restricting Rows - the Where Clause, I talked about the WHERE clause. Select Queries Part 3: Sorting and Grouping (ORDER BY, GROUP BY) showed the Order By and Group By clauses.
In Select Queries Part 1: Simple Queries, I discussed the SELECT and FROM clauses. In Select Queries Part 2: Restricting Rows - the Where Clause, I talked about the WHERE clause. Select Queries Part 3: Sorting and Grouping (ORDER BY, GROUP BY) showed the Order By and Group By clauses.
This time I'm going to discuss a few lesser known but powerful clauses: Top, Distinct, Transform...Pivot, and Parameters.
PREDICATE (optional)
Another less well known section of a SQL statement is the Predicate. The Predicate follows the SELECT keyword and precedes the Field List. There are two important predicates: TOP and DISCTINCT.
Top Predicate
The Top Predicate allows you to display the top(x) values from a query in terms of either a number or percentage. I can't really talk about the TOP predicate without discussing the ORDER BY clause because the rows displayed are determined by the ORDER BY clause.
Examples:
SELECT TOP 10 ProductName
FROM Products
ORDER BY Cost
This will display ten rows of ProductNames whose costs are the LOWEST.
SELECT TOP 25% ProductName
FROM Products
ORDER BY Cost DESC
This will display 25% of the total number of rows of the Product table whose costs are HIGHEST.
In other words, the query creates a standard Select Query, applies the sort order in the ORDER BY clause, then displays just the top X values from the query.
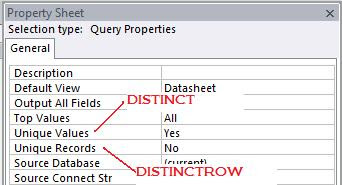
To add a TOP predicate in the Query Builder, go to the Properties of the Query and look for the Top Values property:

A word about duplicates: If there are duplicates in Top rows, they will all be displayed. So, sometimes Top 10 could return 11 or even more rows. It is possible to remove these duplicates with a subquery. To do that and a lot of interesting things with the TOP predicate, download a free database sample from my website called: TopQuery which goes into more detail including:
- Removing Duplicates.
- Top values with Aggregates (Totals Query)
- Top values per Group
- Returning Random X records from your table.
- User input TOP value (parameter).
DISTINCT Predicate
The DISTINCT predicate will remove duplicates from your result set based on the fields in your Field List. For instance, if I had a Products table that looked like this:
ProductName Cost
----------- ----
Ax $3
Hammer $15
Hammer $10
Wrench $5
Wrench $4
SELECT DISTINCT ProductName
FROM Products
Would return:
ProductName
-----------
Ax
Hammer
Wrench
Removing the duplicated rows. The effect is the same as using GROUP BY clause without an aggregate function:
SELECT ProductName
FROM Products
GROUP BY ProductName;
DISTINCTROW
The DISTINCTROW predicate is unique to Access. It will return unique records across the entire record, not just the fields in the Field List.
SELECT DISTINCTROW ProductName
FROM Products
returns:
ProductName
-----------
Ax
Hammer
Hammer
Wrench
Wrench
Honestly, though, I've never found a good use for DISTINCTROW because I always have a Primary Key in all my tables, so all of the rows are already unique.
To create either the DISTINCT predicate in the Query Builder, set the Unique Values property to Yes, to create the DISTINCTROW predicate set the Unique Rows value to Yes.
TRANSFORM...PIVOT (Crosstab Query)
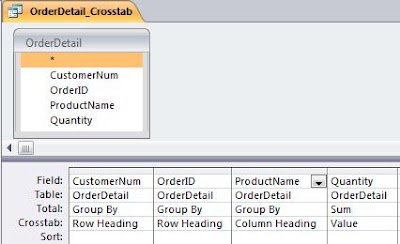
The Crosstab Query is an Access Specific query that allows you to display recordset results in a much more compact form. For instance, if I had an OrderDetail table that looked like this:

I could use a Crosstab Query to show the data like this:

The Crosstab Query used two clauses, the TRANSFORM, which comes before the SELECT statement, and the PIVOT, which follows the GROUP BY. In SQL View, it looks like this:
TRANSFORM Sum(Quantity) AS SumOfQuantity
SELECT CustomerNum, OrderID
FROM OrderDetail
GROUP BY CustomerNum, OrderID
PIVOT ProductName;
In the Query Builder, it looks like this:
The easiest way to learn Crosstab Queries is to use the Crosstab Wizard that's available when you create a New Query.
PARAMETERS Clause (Optional)
Queries can also accept user input. This input is called a Parameter. Parameters are placed in the WHERE clause of a SQL statement and takes the form of a Prompt in square brackets. For example:
SELECT * FROM Customers
WHERE CustomerNum [Enter Customer Number]
When the query is run, a parameter input box appears:

When the user inputs a valid customer number, the query returns the row(s) applicable to the customer entered.
A parameter can also reference a control on a form. Suppose I have a Customer form and I want to see all of the orders associated with a particular customer. I could have a query that looks at the CustomerNum in the current form and return all of the order numbers for that customer.

So if I had a query that looked like this:
SELECT CustomerNum, OrderNumber
FROM Customer INNER JOIN Orders
ON Customer.CustomerID = Orders.CustomerID
WHERE CustomerNum=[forms]![frmCustomer]![CustomerNum]
It would look at the value in the CustomerNum text box on the frmCustomer form and use that as the parameter value to return all the orders for customer 100.
Access does a pretty good job of figuring out what the data type of a parameter is. However, there are times when it gets confused. This is particularly true when trying to use parameters with a Crosstab query. In these cases, you can define what the data type of the parameter will be with the PARAMETERS Clause.
The PARAMETERS clause goes before the SELECT statement in a Select query:
PARAMETERS [Enter Customer Num] Text(255);
SELECT Customer.*
FROM Customer
WHERE CustomerNum=[Enter Customer Number];
Notice the semi-colon at the end.
In a Crosstab query, it goes before the TRANSFORM statement:
PARAMETERS [Enter CustomerNum] Text(255);
TRANSFORM Sum(Quantity) AS SumOfQuantity
SELECT CustomerNum, OrderID
FROM OrderDetail
WHERE CustomerNum=[Enter CustomerNum]))
GROUP BY CustomerNum, OrderID
PIVOT ProductName;
To create parameters in the Design View, choose Parameters from the Design Ribbon (A2007) or from the Query>Parameters Menu (A2003 and before). You will get a dialog box that looks something like this:

.
Monday, November 30, 2015
Select Queries Part 3: Sorting and Grouping (ORDER BY, GROUP BY)
In the first post of this series, Select Queries Part 1: Simple Queries, I talked about creating simple queries with the first two sections of a Select Query, the SELECT clause and the FROM clause. In the second post, Select Queries Part 2: Restricting Rows - the Where Clause, I discussed how to restrict rows returned with the WHERE clause. This time, I'm going to discuss how to sort your results with the ORDER BY clause and how to aggregate your data with the GROUP BY clause.
ORDER BY Clause
Tables in relational databases like Access (or SQL Server or Oracle, for that matter) do not have any intrinsic order. This means they can be returned in any order, not necessarily the order they were entered or that they appear when you open the table. So if you want them in a particular order, you have to sort them yourself. You do that in a query in the ORDER BY clause.
The ORDER BY clause has two parts: [field] [ASC/DESC] (repeat for as many fields as you need).
The [field] designates the field on which the sort will be performed and [ASC/DESC] tells how the field will be sorted. ASC means ascending (smallest to largest). DESC means descending (largest to smallest). ASC is the default, so if you don't designate an order, it will be smallest to largest.
Letters are sorted alphabetically A-Z (or Z-A if DESC). Numbers are sorted numerically. This is all very obvious until you have numbers that are stored as text. While they look like numbers, they will not sort numerically. For instance, these character strings sorted alphabetically:
CustomerNum
-----------
101
102
1100
201
3001
301
One solution is to add leading zeros to your text numbers. Numeric data will not save leading zeros, but text will:
CustomerNum
-----------
0101
0102
0201
0301
1100
3001
Later on, I'll discuss another method that does not require altering your data.
The Order By clause follows the Where clause:
SELECT ProductName, Cost, Price, [Price]-[Cost] AS Margin
FROM Products
WHERE ProductName = "hammer"
ORDER BY Cost DESC
Examples of ORDER BY clauses:
ORDER BY ProductName (Products alphabetically A-Z)
ORDER BY [Price]-[Cost]DESC (margin highest to lowest)
ORDER BY ProductName, Cost DESC
The last example shows that you can also sort on multiple fields. In this case, the table will be sorted on ProductName (ascending) and within each group of products, it will be sorted on Cost (descending).
ProductName Cost
----------- ----
Ax $3
Hammer $15
Hammer $10
Wrench $5
Wrench $4
The fields in the ORDER BY clause do not have to be in the Field List of the SELECT clause. For instance, this will work just fine:
SELECT ProductName
FROM Products
ORDER BY Cost
In the Query Builder, simply uncheck the checkbox to do this:
You can also sort on an expression. I showed [Price]-[Cost], but you can also apply functions to your fields. For instance, earlier I showed how text numbers will sort incorrectly. I showed how leading zeros will correct it, but another solutions is to display the text numbers as they are in the field list, but to add a function to the ORDER BY clause that converts them to numeric.
SELECT [CustomerNum]
FROM Customer
ORDER BY CLng([CustomerNum]);
CLng () is a built-in function that converts Text to Long Integer.
GROUP BY and HAVING Clauses
The GROUP BY and HAVING clauses are used with "Totals" or Aggregate queries.
The GROUP BY allows you to group your data and apply a function to the grouped data. For instance:
SELECT ProductName, Cost
FROM Products
Will result in the following:
ProductName Cost
----------- ----
Ax $3
Wrench $4
Hammer $15
Wrench $5
Hammer $10
However, if I wanted to see the average cost for each group, I could add a GROUP BY clause:
SELECT ProductName, Cost
FROM Products
GROUP BY ProductName, Avg(Cost)
ProductName Cost
----------- ----
Ax $3
Wrench $ 4.5
Hammer $ 12.5
Every field in the Field List MUST be represented in the GROUP BY clause either to group on or with an aggregate function. Examples of aggregate functions are: Sum, Avg, Min, Max, and Count.
The HAVING clause works like the WHERE clause, but it restricts rows after they have been grouped.
SELECT ProductName, Cost
FROM Products
GROUP BY ProductName, Avg(Cost)
HAVING Avg(Cost)
Will return:
ProductName Cost
----------- ----
Wrench $ 4.5
Hammer $ 12.5
There's a lot more to be said about Totals Queries, and I'll do that in greater depth in a later post.
Next time, in Select Queries: Part 4, I'll finish up the Select Query with some odds and ends: Top Query, Distinct Query, Crosstab Query and Parameters.
.
Thursday, November 26, 2015
Select Queries Part 2: Restricting Rows - the Where Clause
In my last post, Select Queries Part 1: Simple Queries, I talked about the first two sections of a Select Query, the SELECT clause and the FROM clause. These allow you to display certain columns from designated tables. The next section is one of the most powerful features of a query: the WHERE clause.
WHERE Clause
The WHERE Clause is one of the most powerful features of a query. It allows you to restrict the rows returned based one or more criteria. These criteria are in the form of an expression, the general form of which is:
WHERE Clause
The WHERE Clause is one of the most powerful features of a query. It allows you to restrict the rows returned based one or more criteria. These criteria are in the form of an expression, the general form of which is:
[Field] <comparison operator> [Value]
The field is a column in the base table(s) or a calculated column. It does not have to be in the Field List. The comparison operators are the standard math comparators: =, <, >, <=, >=, or <>; with some SQL specific ones added: IN/EXISTS, BETWEEN, LIKE, and IS NULL. The value portion can be either a hard coded value (like "hammer" or 25), or it can be another field or expression.
The WHERE clause follows the From Clause in a SQL Statement like so:
SELECT ProductName, Cost, Price, [Price]-[Cost] AS Margin
FROM Products
WHERE ProductName="hammer"
Examples of simple WHERE clauses:
WHERE ProductName="hammer"
(to show all hammers)
WHERE ProductName <> "hammer"
(to show all products EXCEPT hammers )
WHERE Cost <= 0.05
WHERE Price < Cost
(products sold below cost)
WHERE [Price]-[Cost]>2*[Cost]
(where the margin is greater than twice the cost)
LIKE is used with character data only and uses the asterisk as a wildcard symbol:
WHERE ProductName LIKE "ham*"
(returns "hammer" and "hammock")
WHERE ProductName LIKE "*nail"
(returns "10p nail" and "8p nail")
IN allows you to test if a field matches one of a list of values.
WHERE Cost IN (1, 2, 5, 8)
IN can also contain another SQL statement. The SQL statement contained in the IN must have only one field in the Field List.
WHERE ProductName IN (SELECT ProductName FROM Products)
I'll talk more about this in a later post when I discuss subqueries.
BETWEEN allows you to test for a range of values:
WHERE Cost BETWEEN 5 AND 10
WHERE BeginDate BETWEEN #1/1/2008# AND #12/31/2008#
IS NULL is a special comparator that tests whether or not a field is Null. The other comparison operators do not work with Null, so IS NULL is the only way to test for it.
WHERE ProductName IS NULL
Multiple Criteria and Logical Operators
You can also have multiple criteria by using multiple expressions joined by the Logical Operators: AND/OR. Examples of simple multiple criteria:
WHERE ProductName="10p nail" OR ProductName="8p nail"
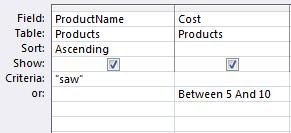
WHERE ProductName="saw" AND Cost BETWEEN 5 AND 10
WHERE ProductName="saw" OR Cost BETWEEN 5 AND 10
Unfortunately, the Query Builder View of WHERE clauses (or Criteria as it's called in the QB) looks quite different than in the SQL View. In the QB, you do not need to repeat the field name with an OR or AND statement like you do in SQL. For instance, if I wanted to display both 10p nails and 8p nails, my WHERE clause would look like this:
WHERE ProductName="10p nail" OR ProductName="8p nail"
But the Query builder would look like this:
Figure 1 
Of course, this would also work:
Figure 2 
You have to be careful when creating multiple criteria in the Query Builder because sometimes they don't say exactly what you think they do. It matters which lines in the Criteria that you put your expressions. You create ORs on separate lines, while you create ANDs on the same line.
So this:
WHERE ProductName="saw" OR Cost BETWEEN 5 AND 10
Translates to:
Figure 3
(Notice the criteria are on separate lines.)
But this:
WHERE ProductName="saw" AND Cost BETWEEN 5 AND 10
Translates to:
Figure 4 
(Notice here the criteria are on the same line.)
It gets even more complicated with multiple ANDs and Ors. For instance, what does this statement mean?
WHERE ProductName="saw" OR ProductName="hammer" AND Cost BETWEEN 5 AND 10
You might think it means I want "saws and hammers with a cost between 5 and 10". However, it doesn't. There is an Order of Precedence to the logical operators as there are with arithmetic symbols. AND always takes precedence over OR. So what will really be returned is "ALL saws and only those hammers that cost between 5 and 10". The AND expression will be evaluated before the OR expression.
So how do I get what I want? The answer is parentheses. If I want something evaluated out of precedence (like my OR expression) I surround it with parentheses. So it would be this:
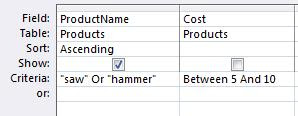
WHERE (ProductName="saw" OR ProductName="hammer") AND Cost BETWEEN 5 AND 10
In the Query Builder, it would look like this:
Figure 5
One last thing about the Query Builder and WHERE clauses. The QB overdoes it with table names and parentheses. If I create the following query in the Query Builder:
Figure 6
I will get the following SQL statement:
SELECT Products.ProductName, Products.Price,
FROM Products
WHERE (((Products.ProductName)="saw"
Or (Products.ProductName)="hammer")
AND ((Products.Cost) In (1,2,5,7)));
Because there is only one table in the query, the table name preceding every field is not necessary. However, it also puts in parentheses, which, while it makes the query technically correct, actually makes it harder to read. Many of these parentheses can be removed, but not all. Naturally, the parentheses that surround the IN list must remain and also the OR statement that we know we want to take precedence. The query can be cleaned to look like this:
SELECT ProductName, Price
FROM Products
WHERE (ProductName="saw"
Or ProductName="hammer")
AND Cost In (1,2,5,7);
Because of the possibility of error when creating complex WHERE clauses in the Query Builder, I usually create them in the SQL View where I know I can control the parentheses.
NOT Operator
There is one more important Logical Operator, and that's the NOT operator. The NOT operator reverses an expression. It can be used with the LIKE, IN, and BETWEEN operators or entire multiple-expression WHERE clauses. It returns all rows EXCEPT those that would have been returned if you hadn't used the NOT.
WHERE ProductName NOT LIKE "ham*"
WHERE Cost NOT IN (1, 2, 5, 8)
WHERE Cost NOT BETWEEN 5 AND 10
WHERE Cost NOT IS NULL
It's important to remember that NOT also reverses both the comparison operators and the other logical operators, so you need to be really careful. For instance,
WHERE NOT(ProductName="saw" Or ProductName="hammer")
Is equivalent to:
WHERE (ProductName<>"saw" AND ProductName<>"hammer")
Next time, I'll look at sorting and groupin in: Select Queries Part 3: Sorting and Grouping (ORDER BY, GROUP BY).
.
Monday, November 23, 2015
Select Queries Part 1: Simple Queries
Select Queries
The most common type of query is the Select Query. Its purpose is to return a dataset that is a dynamic view into your database. In fact, in other SQL dialects, like T-SQL (SQL Server) or SQL*Plus (Oracle) a saved Select Query is called a View.
The Select Query is very flexible and allows you to see your data in a variety of ways.
- You can specify which columns you want to see.
- You can also restrict the rows returned based on one or more criteria.
- You can join multiple tables together on a common field(s).
- You can return unique records, the top or bottom number (or percentage), sort your data on one or more columns.
- And you can make your query interactive by adding parameters.
A Select Query can be created in the Query Builder view or directly in the SQL view. go to the Create Tab on the Ribbon and select Query Design.
The Query Designer (aka QBE) looks like Figure 1. The top pane shows which table or tables on which the query is based. The bottom pane shows which fields will be used in the query and the criteria used to restrict the rows.
Figure 1:
Switching to SQL View will result in the above query to look like this:
SELECT Products.ProductName, Products.Cost, Products.Price
FROM Products
WHERE (((Products.Cost)>=5))
ORDER BY Products.ProductName;
It is fairly easy to learn SQL by creating a query in the Query Builder and switching to SQL View.
Sections of a SELECT Query
In general, a Select Query will look like this:
SELECT [optional Predicate] [Field List]
FROM [Table/Query/Join]
WHERE [criteria to restrict rows]
ORDER BY [Field List] ASC/DESC
SELECT Clause
The Select Clause identifies which fields will be displayed in the result set of the query. The Query Builder always qualifies the field name with the table name, which is not strictly necessary unless the field name exists in multiple tables. This will be important when we talk about Joins, but for now, the Select Clause could also look like this:
SELECT ProductName, Cost, Price
You can also create calculated columns in the Select Clause. For instance, suppose I wanted to know the difference between the cost and the price of a product. I could add a calculation to a new column. In the Query Builder, it would look like this:
Figure 2:

Which would look like this in SQL:
SELECT ProductName, Cost, Price, [Price]-[Cost] AS Margin
You have to give the calculated column a name also called an 'alias', which I decided to call "Margin". In the Query Builder, it goes in front of the calculation. In SQL View, it follows the calculation with the AS keyword. The square brackets ([]) are not strictly necessary here, but there are times that they are. For instance, if you had a space in your field name (Product Name), you would be required to put square brackets around it ([Product Name]).
A word about naming: While Access SQL will allow you to use spaces, odd characters, and reserved words as field names by surrounding them in brackets, there are times when this will get you into trouble. Therefore it is best practice to avoid field and table names which will require brackets. You won't go wrong if you name your objects with letters, numbers, and the underscore only and avoid words like Date, Month, Table and other reserved words. You can find a list of reserved words here:
htps://msdn.microsoft.com/en-us/library/bb208875(v=office.12).aspx
You can also select ALL columns with the asterisk:
SELECT *
The asterisk is not the most efficient way of specifying columns, especially in a large table with many columns. If performance is an issue, you might want to restrict your query to just the columns you need. On the other hand, if your base table structure changes frequently, the asterisk can be useful because you don't have to change your query when you add or remove a column.
FROM Clause
The From Clause specifies the table or tables that form the basis of the query. Ultimately, of course, all the data comes tables, but you are not limited to specifying table names. You can also specify saved queries just as if they were tables. This is useful for creating "stacked" queries, that is, queries that build upon a previous query or queries.
In the Query Builder, the From clause is represented by "tables" in the upper pane (see Figure 1). To add another table or query, right-click in the upper pane and select Add Table in the pop-up box.
In SQL View, the from clause looks like this:
FROM Products (Products being a table in our database)
Or
FROM qryProductsSold (assuming qryProductsSold is a saved query)
Adding the From clause to the query above yields:
SELECT ProductName, Cost, Price, [Price]-[Cost] AS Margin
FROM Products
Another very important function of the From clause is to create Joins, that is, merge the records of two or more tables on common fields. For instance, if I wanted to see all of my Orders and their corresponding Order Details, I can join the Order table and the Order Details table. Figure 3 shows the Query Builder View.
Figure 3

The SQL View looks like this:
FROM Orders INNER JOIN OrderDetails ON Orders.OrderID = OrderDetails.OrderID;
In this case, the fully qualified field name (that is with the table name in front of the field name) is required because the OrderID field exists in both tables.
There's a lot more to be said about Joins, and I'll do that in a later post.
Lastly, it is also possible to use an entire SQL statement in a From Clause by simply putting it in parentheses followed by an alias. In the SQL View, this would be perfectly legal:
SELECT FullName, Address, City, State, Zip
FROM (SELECT [FirstName] & " " & [Lastname] AS FullName, Address, City, State, Zip FROM Customer) AS FullCustomer;
This example is not particularly useful, but it does demonstrate how a SQL Statement can be used as a result set in the From clause. You have to be careful, however, because Access doesn't always handle this well. I'll also talk about that in a later post.
Next time, I'll continue with the Select Query by looking at how to restrict the rows returned (WHERE clause) in Select Queries Part 2: Restricting Rows - the Where Clause
Friday, November 20, 2015
What Is A Query?
What is a query?
A query is a multi-purpose object in Microsoft Access. It can be used to display data from a single table or multiple tables, perform calculations on your data, modify data within your tables, and create or modify the structure of tables, indexes or relationships. Basically, anything that uses Structured Query Language (SQL) is called a query.
It is important to realize that queries are dynamic, that is, they allow you to view or manipulate data stored in your tables. I had one customer who complained that she was losing data from her database. Turned out she was creating queries and then deleting rows from the query that she didn't want to see. She didn't realize that in doing so, she was actually deleting the rows from the table the query was based on.
Query Builder View vs. SQL View
Access has two ways to create or modify a query. The Query Builder View allows you to create queries in a graphical interface. SQL View allows you to create queries directly in the SQL language. The two views are interactive. In other words, a query created in the Query Builder will be viewable and editable in the SQL View and vice versa. A good way to learn SQL is to create one in the Query Builder and view it in the SQL View.
Types of Queries
Select queries
Select queries create a dynamic view into the database. In fact, in other SQL implementations like SQL Server and Oracle, Select Queries are called Views. They allow you to see just what you want out of your tables. You can choose to see all columns or just selected ones. You can also restrict the number of rows based on criteria. (see: Select Queries Part 1: Simple Queries)
Joins
One important feature of a query is its ability to join multiple tables together on one or more common fields. If you have normalized your database properly (see: What is Normalization?), this is how you put your data back together again. For instance, if you had a CustomerID field in two tables: Customers and Orders, you could join the two tables on the CustomerID field to link all Customers with their respective Orders. (see: What is a Join: Part 1 (Introduction))
Aggregate (Totals) Queries
There are times when you want to aggregate your data, that is, you want to group your data and apply some mathematical function each group. The most common functions are sum and average. Access provides a type of query called a Totals Query that will do this.
Crosstab Queries
A Crosstab Query is a special kind of aggregate query, which calculates an aggregate function (like sum or average), and groups the resulting dataset by two sets of values — one down the side and another across the top. Crosstab queries are particularly useful for displaying summarized data in an easy to understand format.
Action Queries (Data Manipulation Language Queries)
Action Queries (also called Data Manipulation Language Queries or DML) make changes to the data in your tables. You can delete all or some records from your table (see Action Queries: Delete Query). You can change the value of a field or fields in all or some records in your table (see Action Queries: Update Query). You can append records to a table, either selecting records from another table or append specific values (see Action Queries: Append Query). Lastly, you can create a new table from selected record from an existing table (see Action Queries: Make-Table Query).
SQL Specific Queries
The only thing SQL Specific queries have in common is that they cannot be represented in the Query Builder window, so once created, you can never go back to the Query Builder window.
DDL Queries (Data Definition Language Queries)
DDL queries (also called Data Definition Language queries) allow you to create new tables and indexes modify existing ones.
Union Queries
Union queries combine one or more tables. However instead of combining them row-wise like the Join, the union combines tables column-wise. (see: Union Query: Part 1)
Pass-through Queries
A pass-through query is used to return records or manipulate data in a server-based database like SQL Server or Oracle. It simply passes the query on to the host database engine, bypassing the Jet database engine altogether. A pass-through query must be written in the SQL dialect of the host engine. For SQL Server, that would be T-SQL. For Oracle, it would be SQL *Plus.
Updateable vs. Non-updateable Queries
A query can be updateable or non-updateable, depending on a lot of conditions. If a Select Query is updateable, you can actually add, delete and modify records in the base table through the query. In Access, the * button on the Navigation Bar will be visible if the query is updateable. It will be grayed out if it is not. The actual conditions under which a query is updateable can be found in the Access Help System.
Action queries can also be updateable or not depending on the same conditions as the Select query. This is based on whether the dataset returned in the FROM clause of the action query is updateable.
Some queries are inherently non-updateable. These include Union queries, Crosstab queries, and Totals queries. Non-updateable queries can only be used to display data. For more detailed information see "This Recordset Is Not Updateable. Why?"
Creating and Using Queries in Code
Some SQL dialects, like T-SQL, allow you to use procedural constructs like IF statements and Loops, in a query. Access SQL does not. However, Access allows you to create and execute queries in Visual Basic procedures through the use of DAO (Data Access Objects), which is a library of objects that allows you to programmatically manipulate the database.
.
A query is a multi-purpose object in Microsoft Access. It can be used to display data from a single table or multiple tables, perform calculations on your data, modify data within your tables, and create or modify the structure of tables, indexes or relationships. Basically, anything that uses Structured Query Language (SQL) is called a query.
It is important to realize that queries are dynamic, that is, they allow you to view or manipulate data stored in your tables. I had one customer who complained that she was losing data from her database. Turned out she was creating queries and then deleting rows from the query that she didn't want to see. She didn't realize that in doing so, she was actually deleting the rows from the table the query was based on.
Query Builder View vs. SQL View
Access has two ways to create or modify a query. The Query Builder View allows you to create queries in a graphical interface. SQL View allows you to create queries directly in the SQL language. The two views are interactive. In other words, a query created in the Query Builder will be viewable and editable in the SQL View and vice versa. A good way to learn SQL is to create one in the Query Builder and view it in the SQL View.
Types of Queries
Select queries
Select queries create a dynamic view into the database. In fact, in other SQL implementations like SQL Server and Oracle, Select Queries are called Views. They allow you to see just what you want out of your tables. You can choose to see all columns or just selected ones. You can also restrict the number of rows based on criteria. (see: Select Queries Part 1: Simple Queries)
Joins
One important feature of a query is its ability to join multiple tables together on one or more common fields. If you have normalized your database properly (see: What is Normalization?), this is how you put your data back together again. For instance, if you had a CustomerID field in two tables: Customers and Orders, you could join the two tables on the CustomerID field to link all Customers with their respective Orders. (see: What is a Join: Part 1 (Introduction))
Aggregate (Totals) Queries
There are times when you want to aggregate your data, that is, you want to group your data and apply some mathematical function each group. The most common functions are sum and average. Access provides a type of query called a Totals Query that will do this.
Crosstab Queries
A Crosstab Query is a special kind of aggregate query, which calculates an aggregate function (like sum or average), and groups the resulting dataset by two sets of values — one down the side and another across the top. Crosstab queries are particularly useful for displaying summarized data in an easy to understand format.
Action Queries (Data Manipulation Language Queries)
Action Queries (also called Data Manipulation Language Queries or DML) make changes to the data in your tables. You can delete all or some records from your table (see Action Queries: Delete Query). You can change the value of a field or fields in all or some records in your table (see Action Queries: Update Query). You can append records to a table, either selecting records from another table or append specific values (see Action Queries: Append Query). Lastly, you can create a new table from selected record from an existing table (see Action Queries: Make-Table Query).
SQL Specific Queries
The only thing SQL Specific queries have in common is that they cannot be represented in the Query Builder window, so once created, you can never go back to the Query Builder window.
DDL Queries (Data Definition Language Queries)
DDL queries (also called Data Definition Language queries) allow you to create new tables and indexes modify existing ones.
Union Queries
Union queries combine one or more tables. However instead of combining them row-wise like the Join, the union combines tables column-wise. (see: Union Query: Part 1)
Pass-through Queries
A pass-through query is used to return records or manipulate data in a server-based database like SQL Server or Oracle. It simply passes the query on to the host database engine, bypassing the Jet database engine altogether. A pass-through query must be written in the SQL dialect of the host engine. For SQL Server, that would be T-SQL. For Oracle, it would be SQL *Plus.
Updateable vs. Non-updateable Queries
A query can be updateable or non-updateable, depending on a lot of conditions. If a Select Query is updateable, you can actually add, delete and modify records in the base table through the query. In Access, the * button on the Navigation Bar will be visible if the query is updateable. It will be grayed out if it is not. The actual conditions under which a query is updateable can be found in the Access Help System.
Action queries can also be updateable or not depending on the same conditions as the Select query. This is based on whether the dataset returned in the FROM clause of the action query is updateable.
Some queries are inherently non-updateable. These include Union queries, Crosstab queries, and Totals queries. Non-updateable queries can only be used to display data. For more detailed information see "This Recordset Is Not Updateable. Why?"
Creating and Using Queries in Code
Some SQL dialects, like T-SQL, allow you to use procedural constructs like IF statements and Loops, in a query. Access SQL does not. However, Access allows you to create and execute queries in Visual Basic procedures through the use of DAO (Data Access Objects), which is a library of objects that allows you to programmatically manipulate the database.
.
Monday, November 16, 2015
What is a Primary Key?
If I have a small company, any individual employee can be distinguished by a combination of First Name, Middle Initial, and Last Name. This combination uniquely identifies each employee.
If I have a larger company, the chances increase that I could have two employees that have the same name. So the name can no longer be used to uniquely identify a record. So instead, I could use a number like Social Security Number.
A primary key is a special kind of index (see What is an Index?) that is composed of a field (SSN) or combination of fields (First/Middle/Lastname), which uniquely identify a record.
A primary key has a number of useful properties.
First, the value in the primary key cannot be duplicated. If it is a single field, that value cannot be repeated. If it is composed of multiple fields, that combination of values cannot be duplicated. So in the samples above, having a primary key would mean that I could not put two "Roger J Carlson"s in my database.
Secondly, the primary key cannot be NULL and no portion of the primary key (in the case of a multiple field key) can be NULL. (See What does NULL mean?). The NULL means the value of the field is unknown. Obviously, if we don't know the value of the fields, we can't guarantee the value is unique. So disallowing NULLS guarantees we have a valid value in the key fields.
Thirdly, in order to create relationships, there must be a unique index on the field. Since by definition, a primary key is a unique index, a primary key makes an ideal join field. I will discuss this in a later post.
There are two basic types of primary keys: Natural Keys and Surrogate Keys.
Natural keys
A natural key is one composed of a field or fields that already exist in the table. In my examples above, both Social Security Number and Firstname/Middle/Lastname are natural keys. Natural keys can be composed of a single field or multiple fields.
It is important to note that a table can only have a *single* primary key. It is incorrect to say that a table has multiple primary keys. In the case of a multi-field primary key, it has a single primary key composed of multiple fields.
Surrogate keys
A surrogate key is an artificially created number. It has no real-world meaning, and is used mostly in relationships with other tables. In Access, you use the Autonumber datatype to create a surrogate key. This number is system-created and is guaranteed to be unique.
The disadvantage of a surrogate key is that it does not have real-world uniqueness. It would be possible to enter two records for Roger J Carlson, each with a different system-created number. To protect against that, you should also create a unique index on those fields that would otherwise create a natural key.
The advantage of a surrogate key is that it will never be affected by real-world changes to the database. It is also much more efficient to join tables on a single number than on multiple text fields.
Opinions differ, but I prefer a surrogate primary key with a separate unique index. This separates the functions of the primary key: the surrogate key for relationships and the unique index to control real-world uniqueness. In this way, if the conditions that effect the real-world uniqueness (as in the case of moving from a small business to a large business mentioned above), the table relationships will not be disturbed.
Creating a primary key in the Access User Interface is easy. Just open the table in Design View. For a surrogate or single field primary key, select a single record and click the Primary Key button.

For a multi-field primary key, just hold the Control [Crtl] key as you select the fields and then click the primary key button.
Why have a Surrogate Key AND a Unique Index
The purpose of a primary key is to create a unique record. But uniqueness from a database engine perspective is not necessarily the same as uniqueness from a real-world perspecive.
Natural keys perform both these functions.
However, surrogate keys only perform one of them, i.e. identifying records for the database engine to join. It does not, however, help the database user very much to identify unique entities.
For instance, suppose I a customer (Roger J Carlson) to a customer table and the surogate key gets assigned a value of 233. Now, another data entry person also enters the same customer. This copy of Roger J Carlson is assigned a value of 245.
Both Roger J Carlson's refer to the same real-world customer. Which one is right? Impossible to know.
So, while the record is unique from the database engine perspective, it's not from a real-world perspective.
To guard against that, when you use a surrogate key, you also need to create a unique index on a field or combination of fields that will uniquely identify the real-world Roger J Carlson.
Once Roger J Carlson has been entered, it will there after be impossible to enter another Roger J Carlson.
Obviously, in a large database, such a unique key wouldn't work. However, I could use Name, Gender, Birthdate (or some other unique combination of real-world attributes).
Wednesday, November 11, 2015
What is an Index?
An index is a method of cataloging the records in a table to increase the speed and efficiency of retrieving them. You can think of it as a library card catalog.
If the stacks in a real-world library represent your table, the library card catalog is the index. The library card catalog stores just the information necessary to identify a particular book: author, title, and genre, plus a number that identifies where the book can be found in the stacks.
With this number, you can go directly to the location of your book. Without it, you would have to start at the beginning of the stacks and look at each book until you found the one you wanted. (This assumes that the books are not stored in any particular order.)
An index works the same way. It stores the value of a field or combination of field and the location of each record that match it. With this information, a query that sorts or searches on the indexed field(s) can go directly to the records. Without it, it has to start at the beginning of a table and look at each record until it finds the ones it wants.
There are a number of different kinds of indexes: simple indexes, multi-field indexes, unique indexes, and clustered indexes.
Simple indexes are indexes on a single field. They may or may not allow duplicate values. Their main use is for searching and sorting records in a table.
Multi-field indexes are indexes across multiple fields. These also may or may not allow duplicate values. This is different than having simple indexes on multiple fields. In a multi-field index, the combination of records is indexed.
Unique indexes do not allow duplicate values. They may be either simple or multi-field. If it is multi-field, it will allow duplicates in individual fields within the indexed fields, but it will not allow a duplicate across the all of the fields in the index. This is useful to make sure you don't have duplicate records in your table.
Clustered indexes control how the records are stored in the database. If you have a clustered index, the records will actually be stored in that order. A table can have only one clustered index. This makes sense since records in a table can only be physically stored in one order.
Primary Keys are a special type of index. In Access, the primary key is both a unique index and a clustered index. It has one additional property in that no field in the index can be NULL. (see What does NULL mean? ). There can be only one primary key in a table. For more on primary keys, their creation and uses see: What is a Primary Key?
How do you create an index?
For simple indexes, it's easy. Just go to the Design View of the table and select a field. In the Properties, you'll see an Indexed property. Select one of the "Yes" options. To make it a unique index by selecting Yes (No Duplicates).
For multi-field indexes, it's a little more complicated. The simplest thing to do is create a simple index on the first field in your index.
![image_thumb[10]](https://lh3.googleusercontent.com/-Ajqf9IT9IBw/Vp4lH2ITCmI/AAAAAAAAB44/VZDJun0Ke_c/s1600-h/image_thumb%25255B10%25255D%25255B2%25255D.png "image_thumb[10]")
Then on the line directly below it, add another field WITHOUT giving it an Index Name. If the Index Name field is blank, Access will assume the field is part of the index directly above it.
![image_thumb[8]](https://lh3.googleusercontent.com/-USzO1rC3WCY/Vp4lKHPldeI/AAAAAAAAB5I/BuaxKsiQk1M/s1600-h/image_thumb%25255B8%25255D%25255B2%25255D.png "image_thumb[8]")
Add as many fields to the index as you want. From the Indexes Window, you can also set the Unique, Primary, and Allow Nulls properties.
A word of warning about indexes. While they do speed up the retrieval of records, they also slow down the insertion of records. Every time a new record is added, all the indexes need to be rebuilt. If you have too many indexes and a lot of records, this can be a problem. Therefore, it is best to just index those fields that really need indexing. These would include fields that you will be sorting or searching on or fields that participate in Relationships or Joins.
Sunday, November 8, 2015
What does NULL mean? How is it different than the Empty String?
One database concept given to much misunderstanding is the NULL value. What is it?
Null means that the value is unknown. This is different from the Empty String. The Empty String ("") means we know what the value is, and the value is, well, empty. That is, we know that there ISN'T a value.
Consider the case of the middle initial. Some people have a middle initial and some don't. Of those that do, we may or may not know what it is. If I leave it Null, it says that I don't know whether they have one or not. However, I can set the field to "" (Empty string) which says that they DO NOT have a middle initial.
Why is this difference important? Primary keys, for one thing.
Let's assume that my primary key is a composite key composed of FirstName, MiddleInitial, LastName. A primary key CANNOT have a Null as a part of it, thus we can set the value of MiddleInitial to "", and it will accept it. But we cannot leave the value Null.
Why can't a Primary Key have a Null value? Well aside from the fact that Access won't let it, the fact that Null means "I don't know the value" means that it cannot positively guarentee that the field is unique, which is one of the properties of the primary key.
The following four subs illustrate the differences:
Sub test()
If Null = Null Then
MsgBox "True"
Else
MsgBox "false"
End If
End Sub
Running this sub will ALWAYS evaluate to False. Why? Because we don't know what the value of NULL is, so we can't say if it's equal to NULL.
Sub test2()
If IsNull(Null) Then
MsgBox "True"
Else
MsgBox "false"
End If
End Sub
This evaluates to True because the IsNull() is specifically designed to test for NULL.
Sub test3()
If "" = "" Then
MsgBox "True"
Else
MsgBox "false"
End If
End Sub
This evaluates to True because the empty string is a known value.
Sub test4()
If IsNull("") Then
MsgBox "True"
Else
MsgBox "false"
End If
End Sub
False because "" is known, therefore it cannot be unknown.
As I said, NULL=NULL always evaluates to False. Since we don't know the value of Null, we can't say what it equals. This is why you never use NULL this way, but always use the IsNull() function.
Further, Len(Null) does evaluates to Null, as indeed do most things you *compare* with or *do to* Null, ie. Null=Null, X=Null, Null=True, cint(Null), etc.
Len("") ("" representing the 'Empty String' or 'Zero Length String') evaluates to 0 (zero). Because the length of a string of zero length is zero (duh!, my daughter would say).
The problem with explaining NULL, is all the good words are used for something else. You can't define it with itself, so saying "Null is Null" is null content (forgive the expression). You can't use "nothing", because that is an object pointer used to de-allocate object variables. You can't use "empty", because that is a constant specifically for use with a Variant variable. You can't use Zero either, because that represents a specific numeric value, rather than the absence of a value.
I guess we'll have to blame E.F. Codd who declared that any relational database implementation must have a special value called "Null" which represents the "absence of anything" or “unknown” condition for all datatypes.
The best we can do is to say that the value of Null is 'we don't know', which is not to say that we don't know what Null is ... I'd better stop there.
Friday, April 17, 2015
New Video: Ambiguous Outer Joins
In conjunction with Webucator Training Services, I'm pleased to present a video version of one of my most popular posts: Ambiguous Outer Joins
Direct link: https://youtu.be/xLuSwE_AFOM
Subscribe to:
Comments (Atom)