So I'm going to talk about another way to approach normalization that starts with the individual pieces and builds it up into properly normalized tables. This method is called the Entity-Relationship method and the final result is an Entity-Relationship Diagram. An E-R diagram is useful not just for creating the data model, but for documenting it as well.
Since we've been working with the Employee Database in our other examples, let's stick with it. But since I claimed that E-R method works for more complicated designs, let's make it a little more complex. I like to start with a short narrative of the requirements.
Narrative
ZYX Laboratories requires an employee tracking database. They want to track information about employees, the employee's job history, and their certifications. Employee information includes first name, middle initial, last name, social security number, address, city, state, zip, home phone, cell phone, email address. Job history would include job title, job description, pay grade, pay range, salary, and date of promotion. For certifications, they want certification type and date achieved.
An employee can have multiple jobs over time, (ie, Analyst, Sr. Analyst, QA Administrator). Employees can also earn certifications necessary for their job.
Next, I take the narrative and underline all of the nouns. (I'm going to bold them here because Blogger doesn't have underlining.)
Narrative 2
ZYX Laboratories requires an employee tracking database. They want to track information about employees, the employee's job history, and their certifications. Employee information includes first name, middle initial, last name, social security number, address, city, state, zip, home phone, cell phone, email address. Job history would include job title, job
description, pay grade, pay range, salary, and date of promotion.
For certifications, they want certification type and date achieved.
All of these nouns must be represented in the database -- some as Entities and some as Attributes. An Entity is a "thing" about which we store information. An Attribute is the information that is being stored.An employee can have multiple jobs over time, (ie, Analyst, Sr. Analyst, QA Administrator). Employees can also earn certifications necessary for their job.
So the next task is to group the nouns into logical groupings. At first pass, it appears that there are three entities: Employee Information, Job History, and Certification. It is useful at this point to put them in a grid and assign the rest of the attributes like Figure 1.
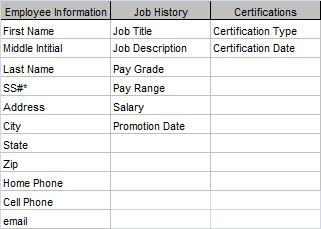
Next, I need to assign primary keys to each entity. (At this point, I call them "entities" rather than "tables".) As I said in What Is A Primary Key?, a primary key is a field or fields which uniquely identify a record. At this point, I'm dealing only with natural keys. Figure 2 shows the primary keys.
Figure 2: Attribute Grid with Primary Keys 
Now we go back to our entities and look for two things:
- see if each attribute can have only one value for that entity, and
- see if each attribute truly belongs to the entity.
To determine the second, we look at "functional dependencies", which just means that each field's value depends on the value of the primary key.
So, for the Employee table, a person (as represented by the SS#) can have only one first name, last name, address, home phone, and so forth. That satisfies requirement #1. Secondly, if the value of the SS# changes, then so will all of those values. By that, I mean if we move to a different entity with a different SS#, that entity will have a different first name, last name, etc. (For our purposes here, we will assume that no two employees share any of these attributes.)
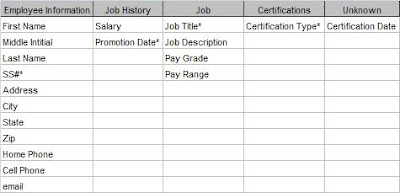
Now, what about the Job History table? Any time an entity has a compound primary key, you should look at it very closely to make sure all the fields depend on the entire primary key. Any particular job can have only one description, pay grade, and pay range. However, none of those depend on the Promotion Date.
I've got a problem here and I need to take another look. What I really have is information about two different "things".
Job Title, Description, Pay Range and Pay Grade pertain to the Job as a category. Everyone who holds that position will have the same values. On the other hand, Salary and Promotion Date will be different for each person. So I really have two entities: 1) Job (information about the job itself), and 2) Job History (information about a particular employee's employment history.
I need take Job Title, Description, Pay Range and Pay Grade out of the Job History table and put them in the Job table.
Lastly, in the Certification table, Certification Date is also not fully dependant on the Certification Type. Different individuals achieve the certification at different dates. I don't have an entity to put the date in, so I'll put that to the side and come back to it later.
Figure 3 shows the amended grid.
At this point, it is useful to look at the Relationships between these Entities. We may be able to find a place to put our unassigned attribute. But I'll save that for the next post: Entity-Relationship Diagramming: Part II.
.







