So far in this series, I've discussed the problem with querying textual or Boolean (Yes/No) data from repeated columns. But numeric data offers new challenges because we often want to do math on them. The most common kind of math is aggregation, that is, summing, counting, and averaging numeric values. This time, I'll talk about counting data in repeated columns.
Others in this series:
- Multiple ORs
- Multiple Unions
- Multiple Joins
- Multiple Ifs
- Impossible Joins
- Summing
- Counting (this post)
- Averaging
Counting Across Columns
The ability to count values is useful in a number of applications. In Excel, there is a Count function which will count the cells that have a value. The Excel function will work for any range of cells, across or down.
In Access, however, the Count() function only works down columns, not across columns. So, counting values in repeated rows is easy (see below), but just like summing, counting across repeated columns is more challenging.
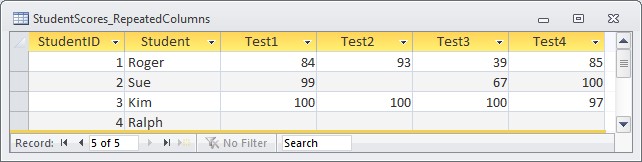
For instance, suppose I had a table of student test scores:

If I wanted to count the number of tests each student has taken, I need to create an expression that will return a 1 if the field has a value and a 0 if it does not. In this way, I can sum the returned values and that will equal the number of fields that have a value.
To do this, I need 3 stages.
1. Checking for NULL
To test whether a field has a value or not, I can test for a NULL value. In Access a blank column is NULL, which does NOT mean either "zero" or "empty string"(see What does NULL mean? How is it different than the Empty String?). To test for a NULL, I have to use the IsNull() function. Like this:
IsNull([Test1])
This will return a value of -1 (Yes) if the field is NULL and 0 (No) if it is not.
2. Checking for NOT NULL
Unfortunately, this is the opposite of what I want. I want a Yes if the field has a value and a No if it does not. To correct this, I can reverse the value returned by the IsNull() function by prefacing it with the NOT operator:
Not IsNull([Test1])
This will return a value of -1 if the field is NOT NULL and 0 if it is. So now I can sum my columns:
(Not IsNull([Test1])) + (Not IsNull([Test2])) + (Not IsNull([Test3])) + (Not IsNull([Test4]))
Note: the extra parentheses around the individual expressions are necessary to evaluate properly.
3. Returning the Absolute Value
This is close, but not exactly what I want because it will return a negative value for the sum. One last thing I have to do is return the absolute value of the returned value:
Abs((Not IsNull([Test1])) + (Not IsNull([Test2])) + (Not IsNull([Test3])) + (Not IsNull([Test4])))
Putting them all together
The full query would look like this:
SELECT Student, Abs((Not IsNull([Test1]))+(Not IsNull([Test2]))+(Not IsNull([Test3]))+(Not IsNull([Test4]))) AS TestCount
FROM StudentScores_RepeatedColumns
ORDER BY Student;
Or in the Query Builder:

The result would look like this:

Count Down Rows
By contrast, suppose I normalize the table to remove the repeated columns. The table should look something like this:

Since the table is normalized (that is, the values go down a row), I can use the aggregate (or "Totals") functions that are built in to SQL. In this case, it's the Count() function.
Count(Score) AS TestCount
That's it. The Count() function has the test for NULLs and absolute value already built in, so you don't need to worry about that at all.
The full query would look like this:
SELECT StudentID, Count(Score) AS TestCount
FROM StudentScores_Rows
GROUP BY StudentID
ORDER BY StudentID;
Or in the Query Builder:

Once again, the results of the queries are identical:

Now, with only 4 test scores, the expression to count repeated columns is manageable. But what if there were 20 or 50? The expression quickly becomes long and cumbersome. But with the normalized structure, the query doesn't change no matter how many test values there are.